Transpiler in Prophecy allows large enterprises to easily upgrade their data integration stack from Ab Initio to modern cloud solutions that can run on data platforms like Databricks. Transpiler converts your existing workflows into low-code visuals and highly optimized open-source Spark code with an accuracy close to 80%. This automation significantly reduces manual effort and costs associated with the migration process for large enterprises.
We’ll show you step-by-step how to use Transpiler for converting a simple graph/workflow that was designed in Ab Initio. By the end of this training, you’ll have a basic understanding of Transpiler and its capabilities. Let’s dig in!
You will need
1. Export Ab Initio Files
To use Transpiler for migrating a graph from Ab Initio, first you will need to have a pre-existing graph created in Ab Initio. Then you will have to export the graph artifacts from Ab Initio. After exporting, look for the below-mentioned files, as Transpiler will use them:
-
** Mp files ** : Mp (meta programming) files contain information about the graph like components used in the graph, number of parallel instances and resource specifications for components in a graph as shown below:
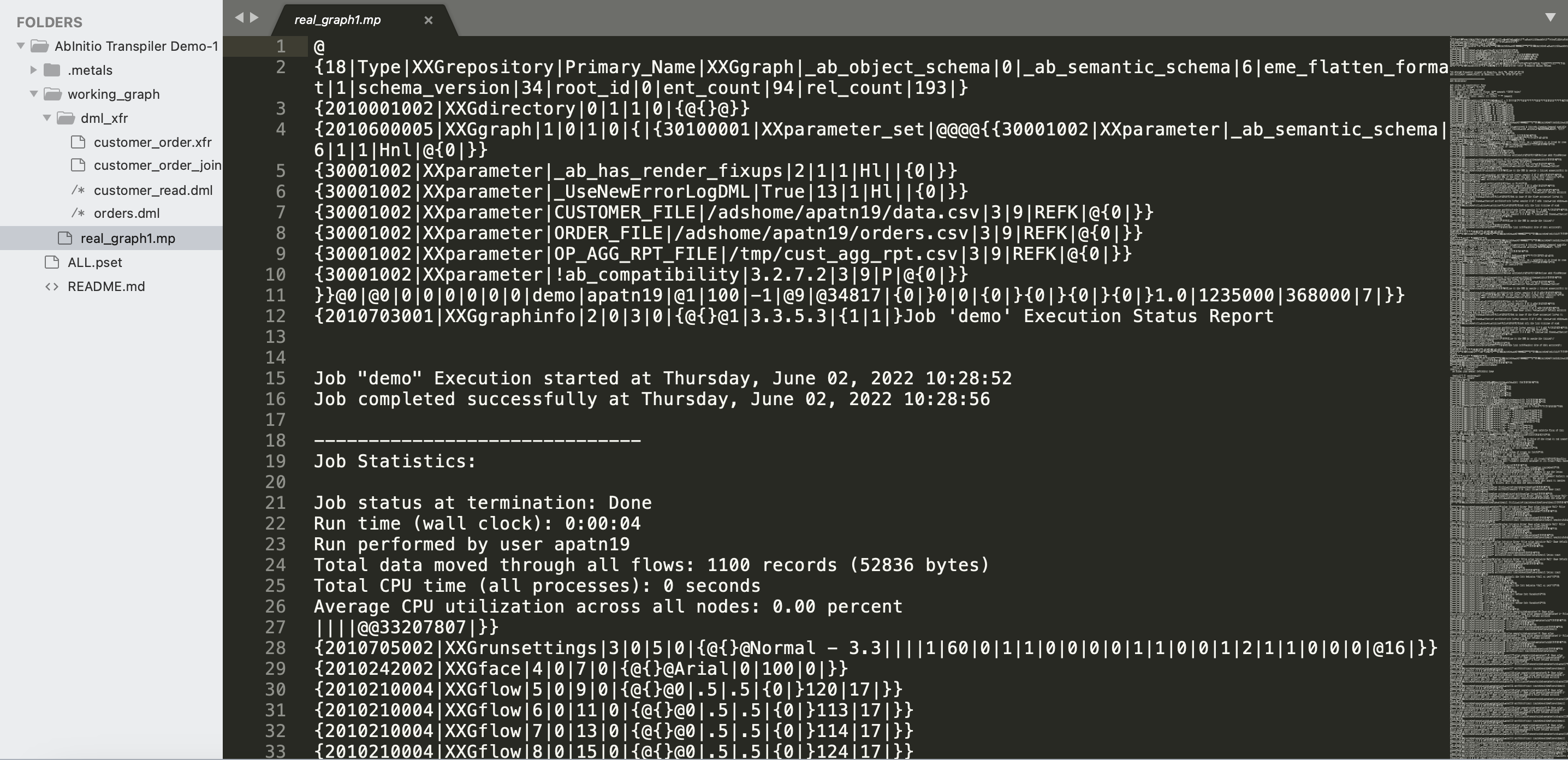
-
** Pset files ** : Pset (parameter set) files store and manage parameter values for the graph, thus allowing you to run the same graph differently by passing dynamic values at the run-time as shown below:
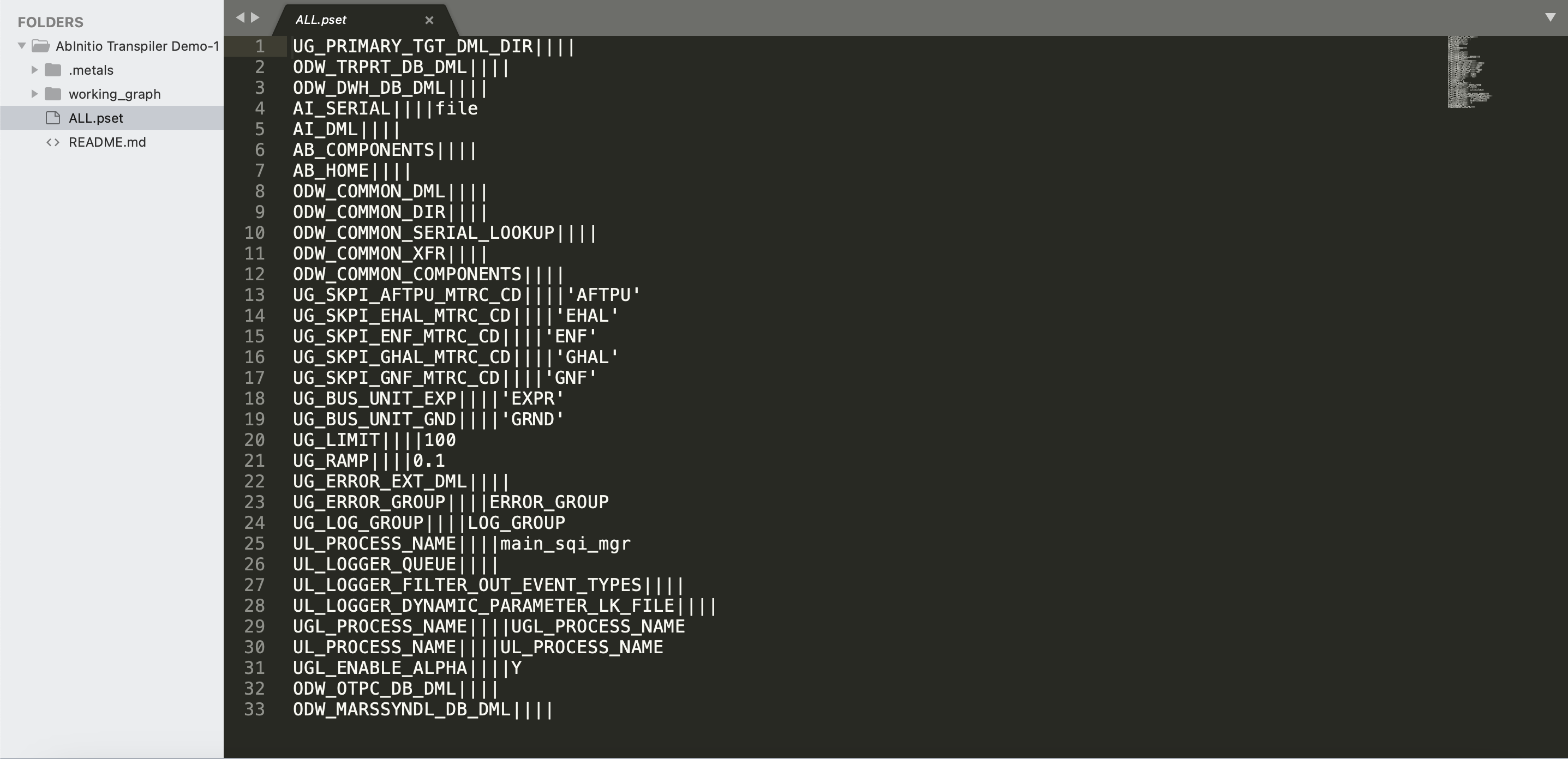
-
** Xfr files ** : Xfr (transform) files contain transformation logic for the graph components. Example of a join component with the transform logic has been shown below:

-
** Dml files **: Dml (data manipulation language) files are used to define the structure of the data records so that data is processed correctly inside the graph component. Example of a component is shown below that defines the schema of a table that will be read and processed.
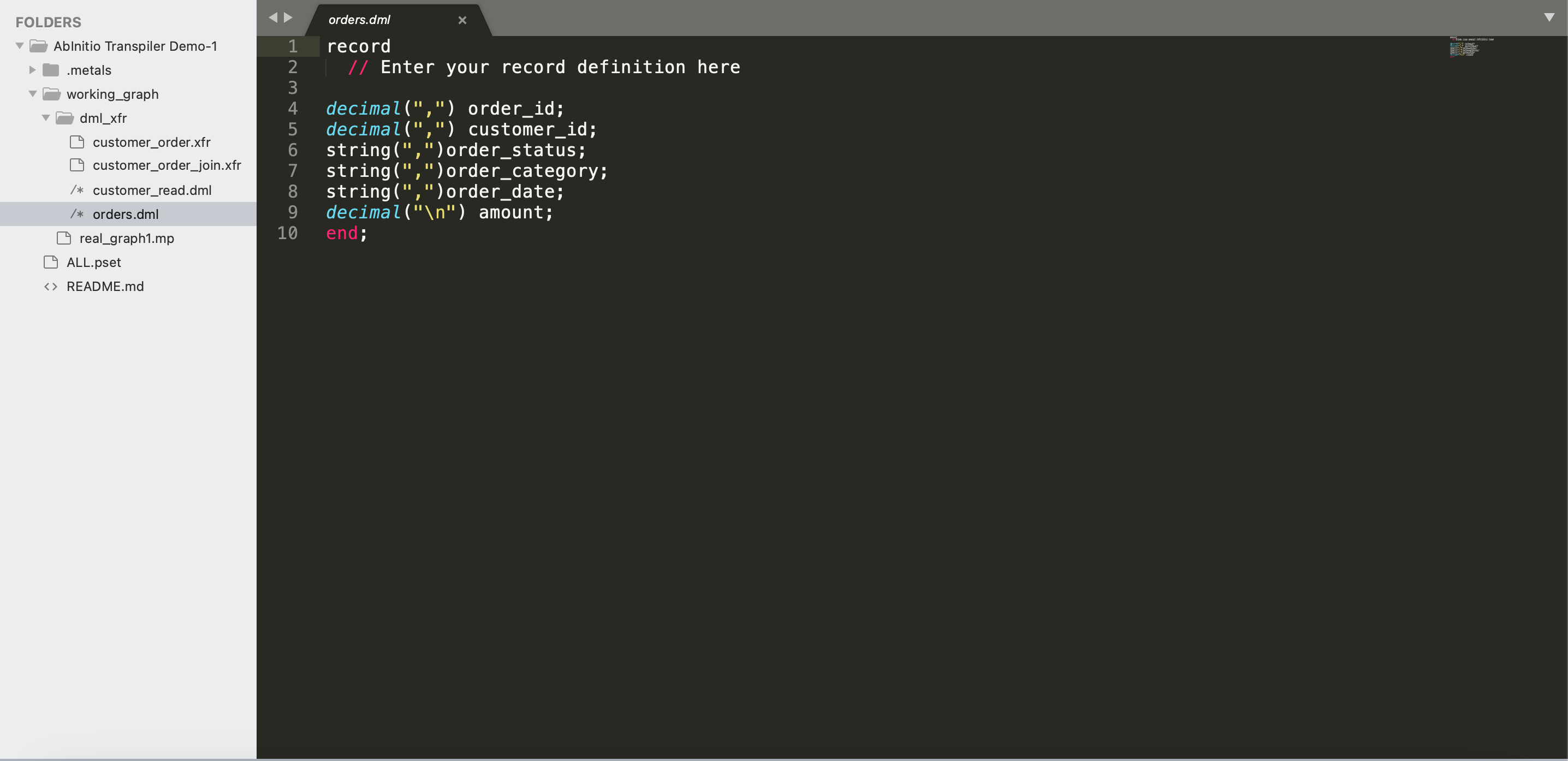
As you have access to all the Ab Initio files now, compress them in a zip folder (recommended) and let’s try to use the same in Transpiler.
2. Import Bundle
To import a bundle into the Transpiler:
- Open the Transpiler interface from the left sidebar of Prophecy.
- Click Import Bundle to import a new bundle.
2.1 Select Source Type
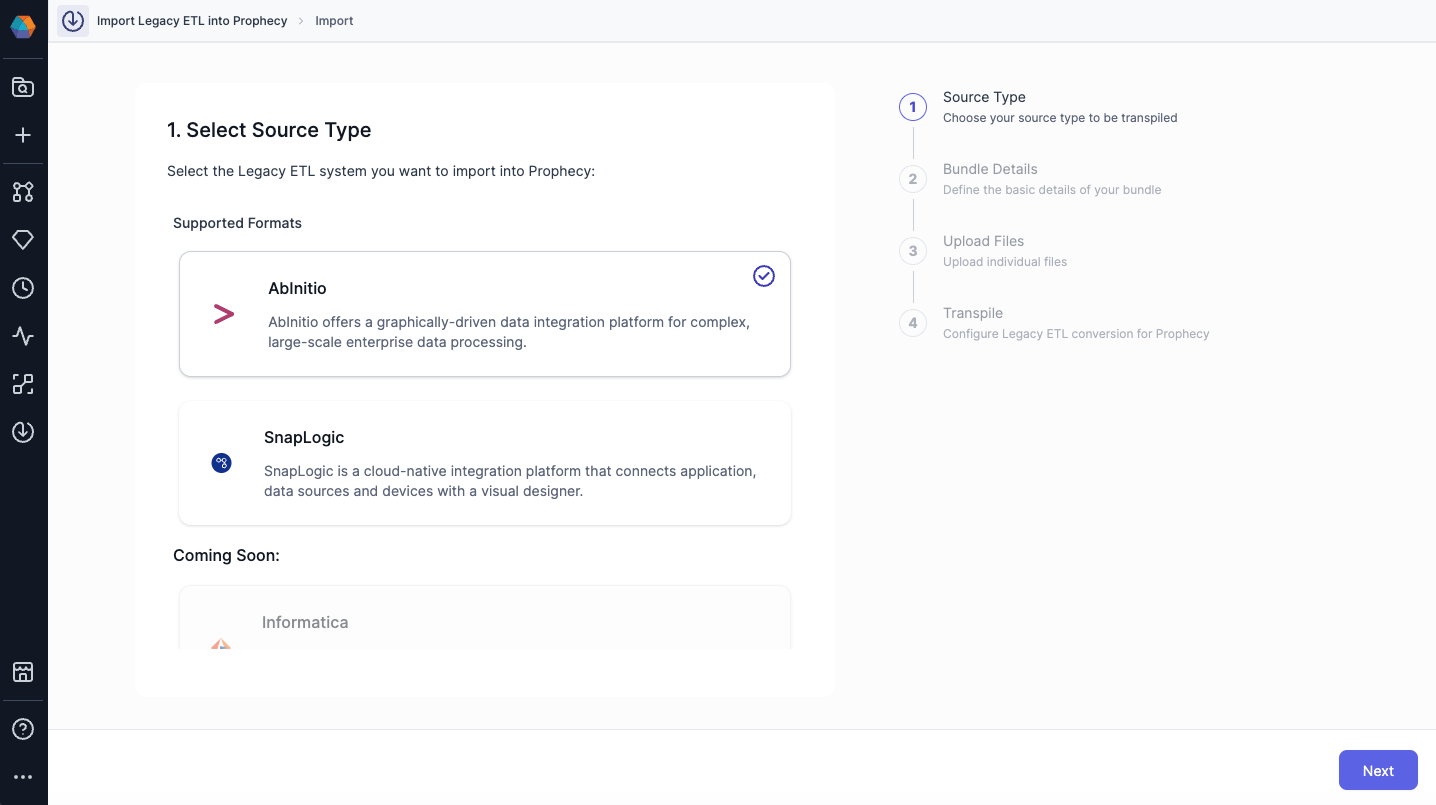 Source Type refers to the Legacy ETL product from which we want to import the files into Prophecy. As you are using Ab Initio, select the same and click on the Next button.
Source Type refers to the Legacy ETL product from which we want to import the files into Prophecy. As you are using Ab Initio, select the same and click on the Next button.
2.2 Enter Bundle Details
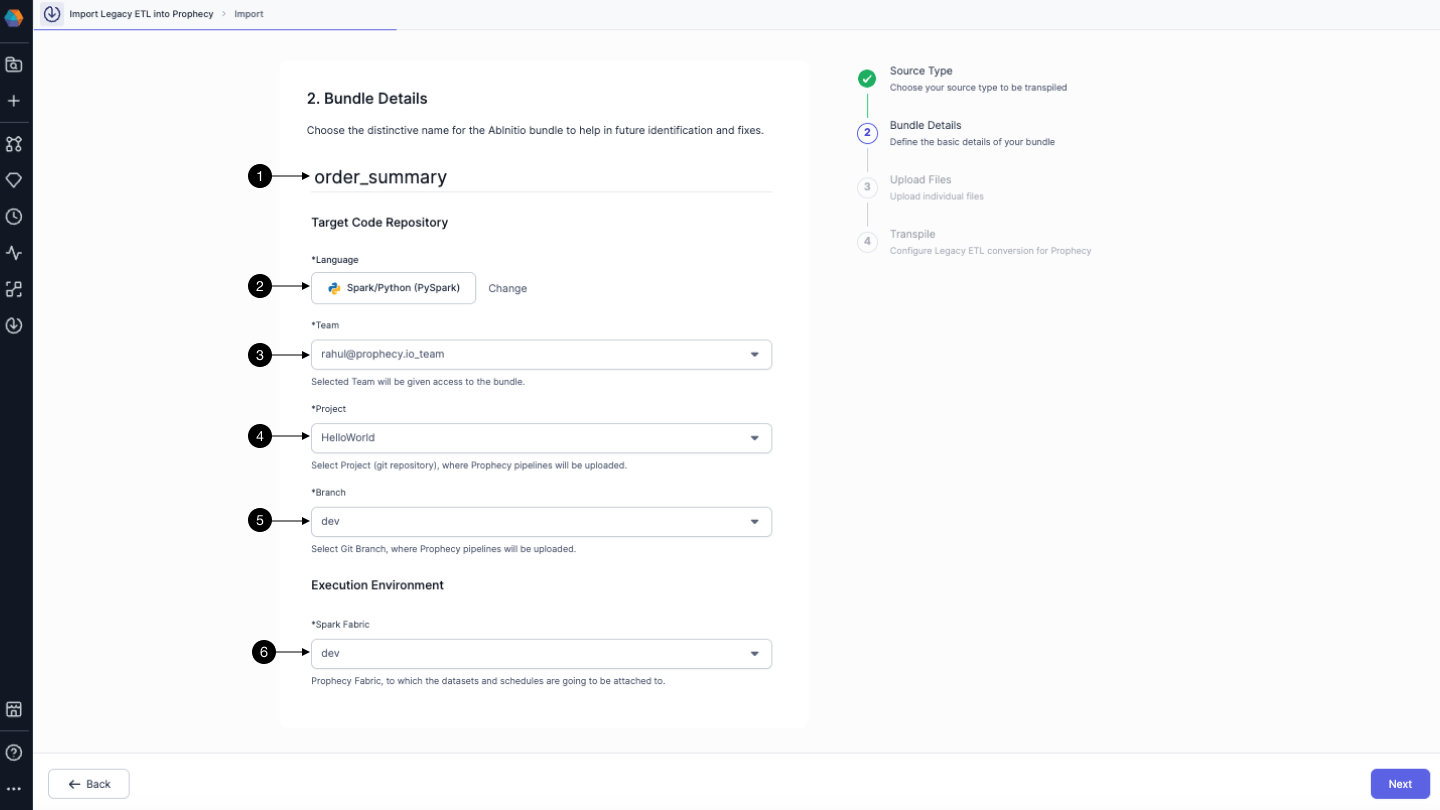 Bundle in Transpiler is like a project where all the details like Ab Initio files, pipelines etc. will be stored for future reference. Creating a bundle is pretty straightforward. First, give a (1) name to your bundle. Select the (2) language in which you want the Transpiler to generate the open-source code for you. Then, select the (3) team to whom you want to have access to the bundle. More teams can be added later. Choose the (4) project where the Prophecy graph will be uploaded and (5) Git branch where all the open-source code will be stored. Finally, you have to select the (6) Fabric where the graph will run. We will be selecting Databricks fabric for now.
Bundle in Transpiler is like a project where all the details like Ab Initio files, pipelines etc. will be stored for future reference. Creating a bundle is pretty straightforward. First, give a (1) name to your bundle. Select the (2) language in which you want the Transpiler to generate the open-source code for you. Then, select the (3) team to whom you want to have access to the bundle. More teams can be added later. Choose the (4) project where the Prophecy graph will be uploaded and (5) Git branch where all the open-source code will be stored. Finally, you have to select the (6) Fabric where the graph will run. We will be selecting Databricks fabric for now.
2.3 Upload Artifacts
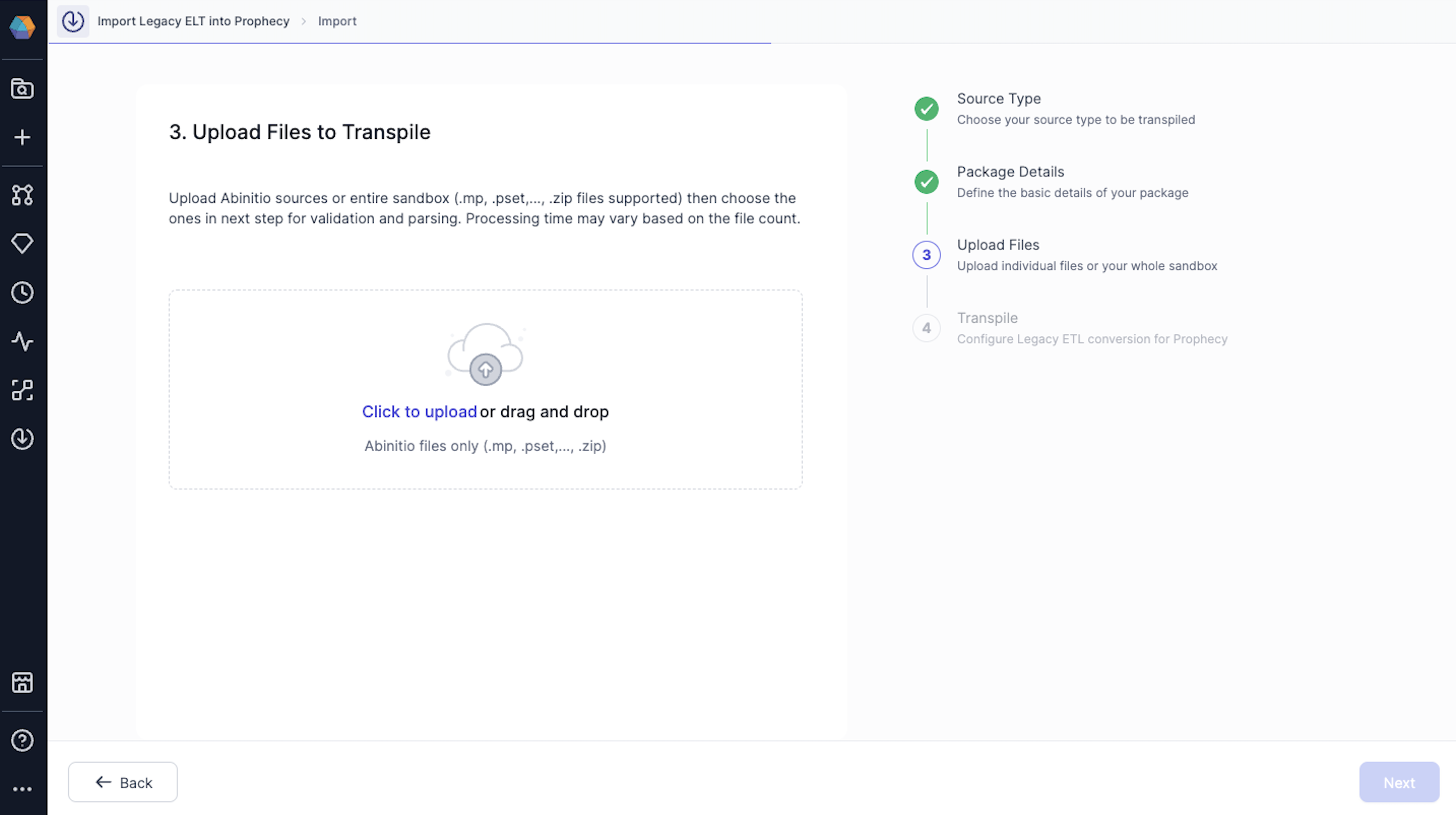 Upload the Ab Initio zip file that you want to transpile and click on the Next button.
Upload the Ab Initio zip file that you want to transpile and click on the Next button.
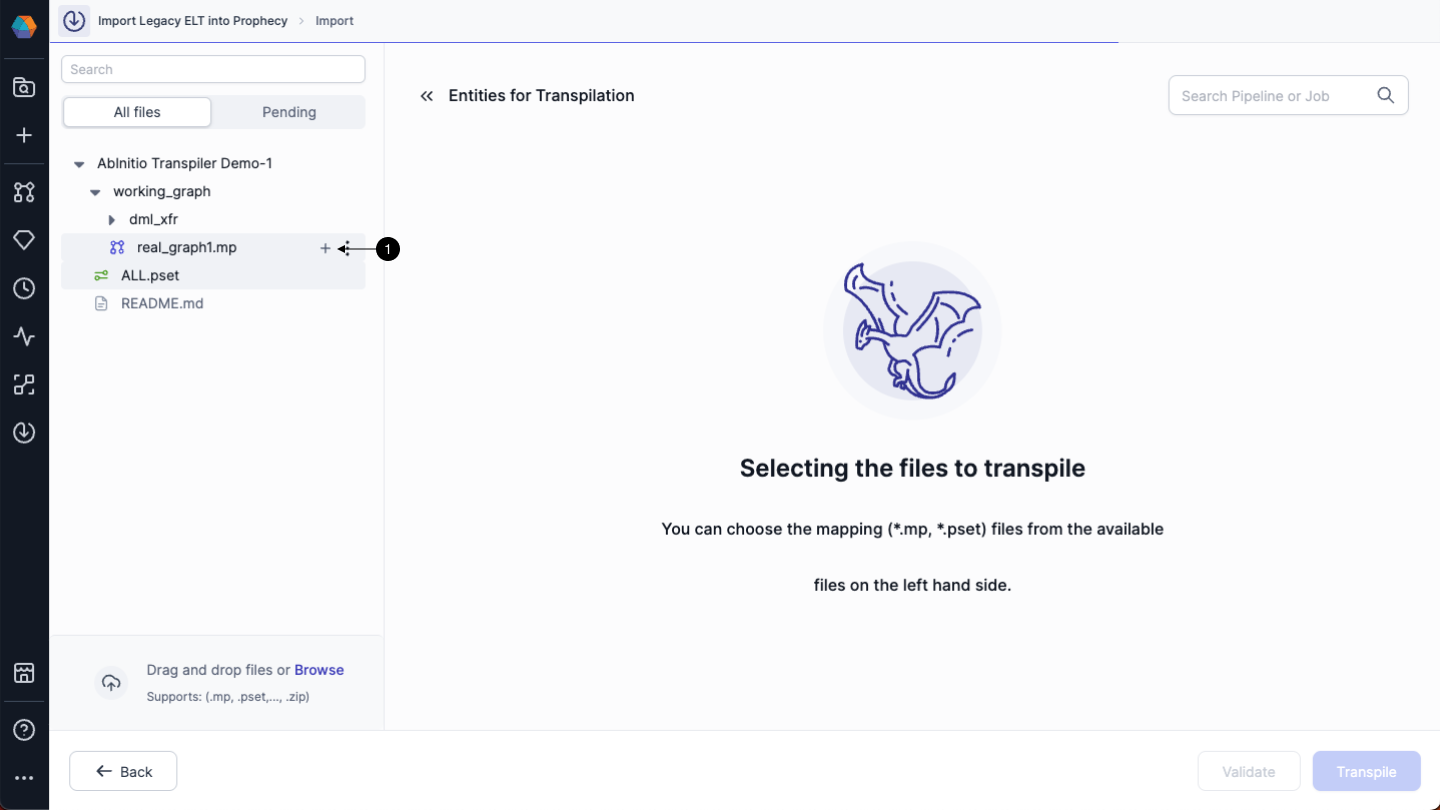 Now, you have to add the (1) mp file that you want to transpile. The Ab Initio graph will be converted to a pipeline in Prophecy.
Now, you have to add the (1) mp file that you want to transpile. The Ab Initio graph will be converted to a pipeline in Prophecy.
 (1) Provide a readable name to the pipeline. Also, add relevant (2) pset files to the mp file, so that Transpiler can read the parameters and generate the pipeline with high accuracy.
** Note **: Configuration pset is required for transpiling generic Ab Initio frameworks. Stay tuned for more information on configuration psets coming soon.
(1) Provide a readable name to the pipeline. Also, add relevant (2) pset files to the mp file, so that Transpiler can read the parameters and generate the pipeline with high accuracy.
** Note **: Configuration pset is required for transpiling generic Ab Initio frameworks. Stay tuned for more information on configuration psets coming soon.
3. Validate and Transpile
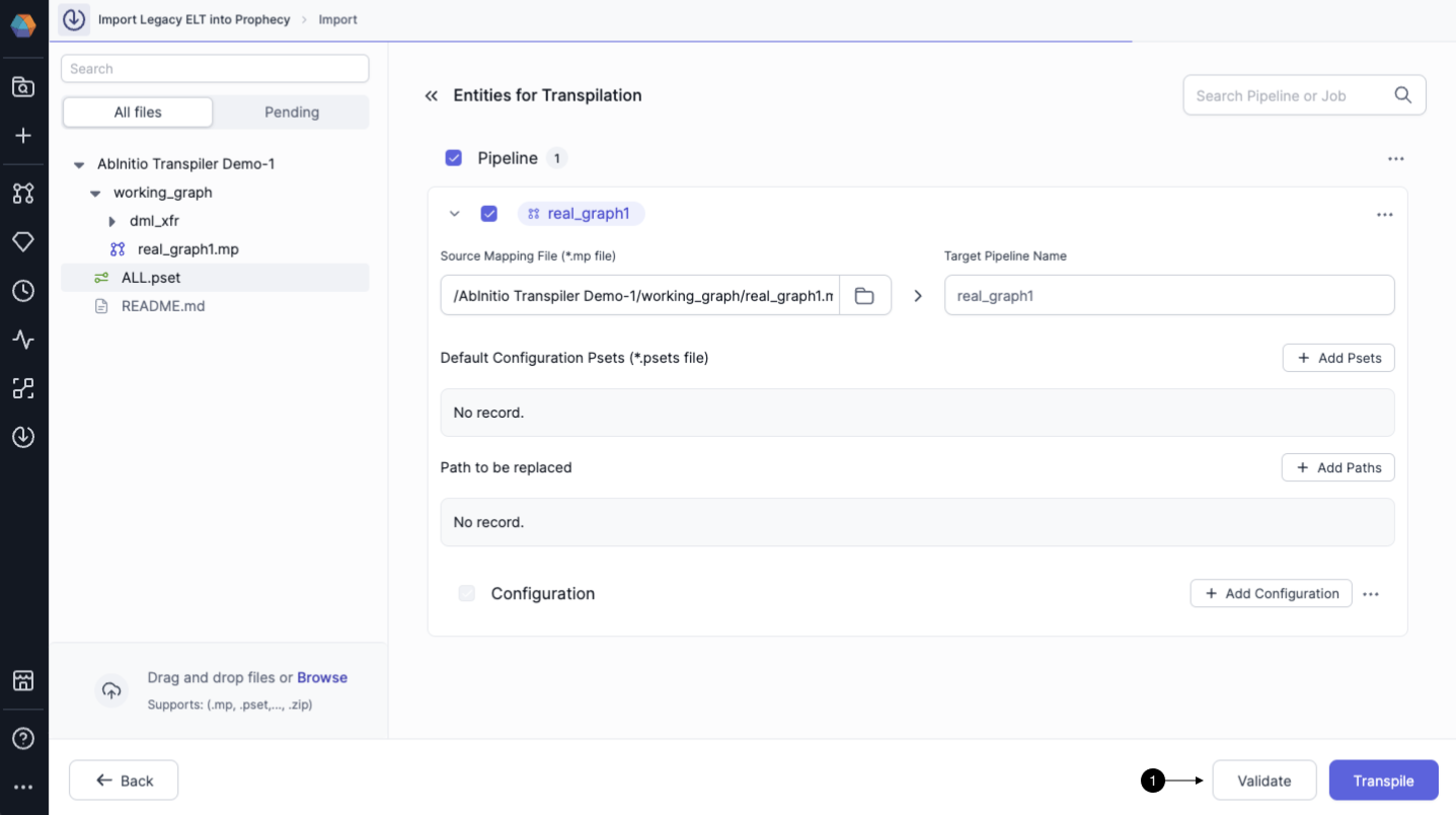 It is always advisable to (1) validate the uploaded files before running transpilation so that you know beforehand if any important files are missing. For higher Transpiler coverage, please make sure to upload the correct mp, pset, xfr and dml files before starting the transpilation process.
It is always advisable to (1) validate the uploaded files before running transpilation so that you know beforehand if any important files are missing. For higher Transpiler coverage, please make sure to upload the correct mp, pset, xfr and dml files before starting the transpilation process.
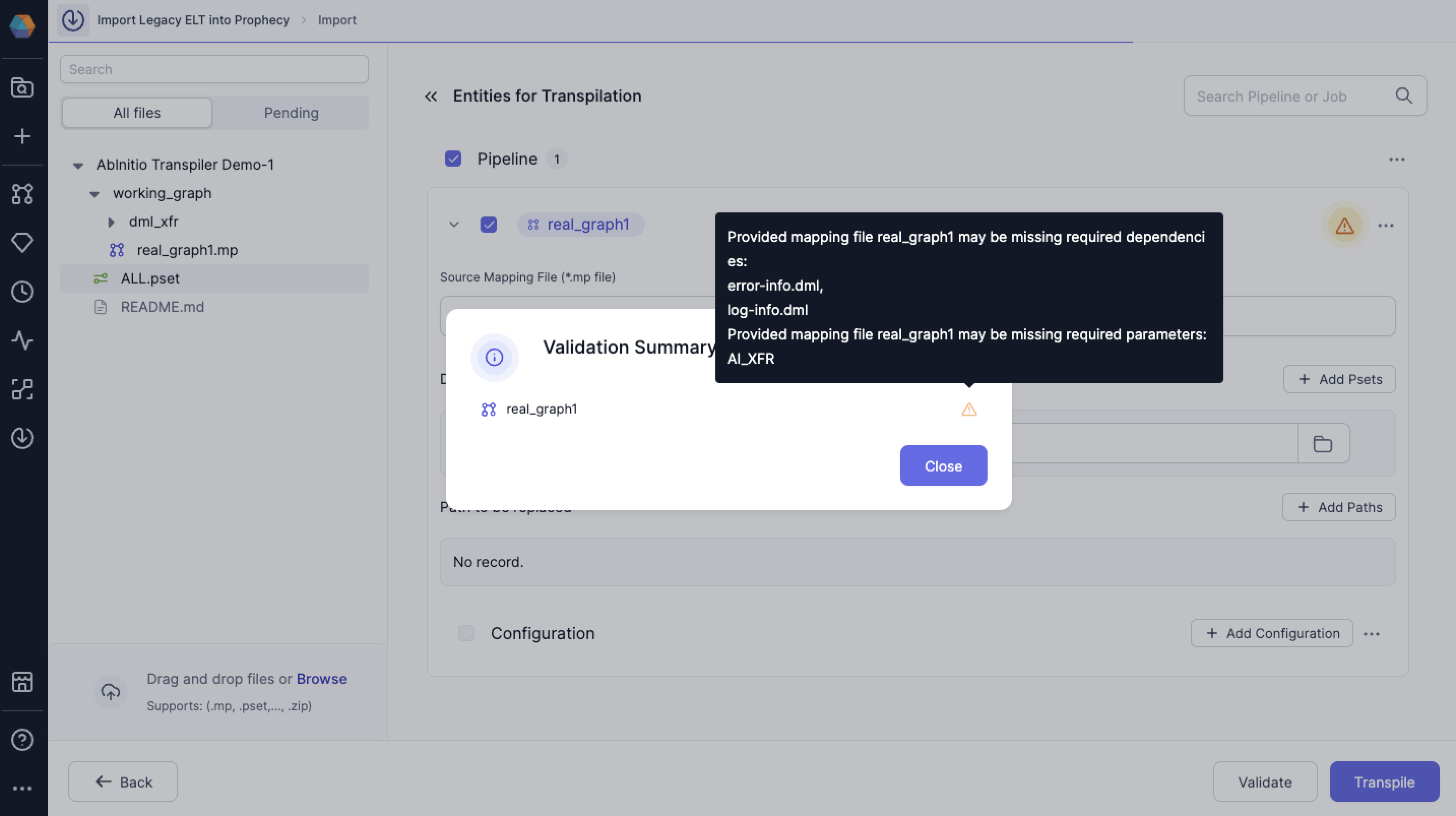 Please feel free to ignore the warning message during validation if you are sure that all the Ab Initio files for the graph have been properly uploaded. Close the validation summary pop-up and click on the Transpile button after you are sure from your side.
Please feel free to ignore the warning message during validation if you are sure that all the Ab Initio files for the graph have been properly uploaded. Close the validation summary pop-up and click on the Transpile button after you are sure from your side.
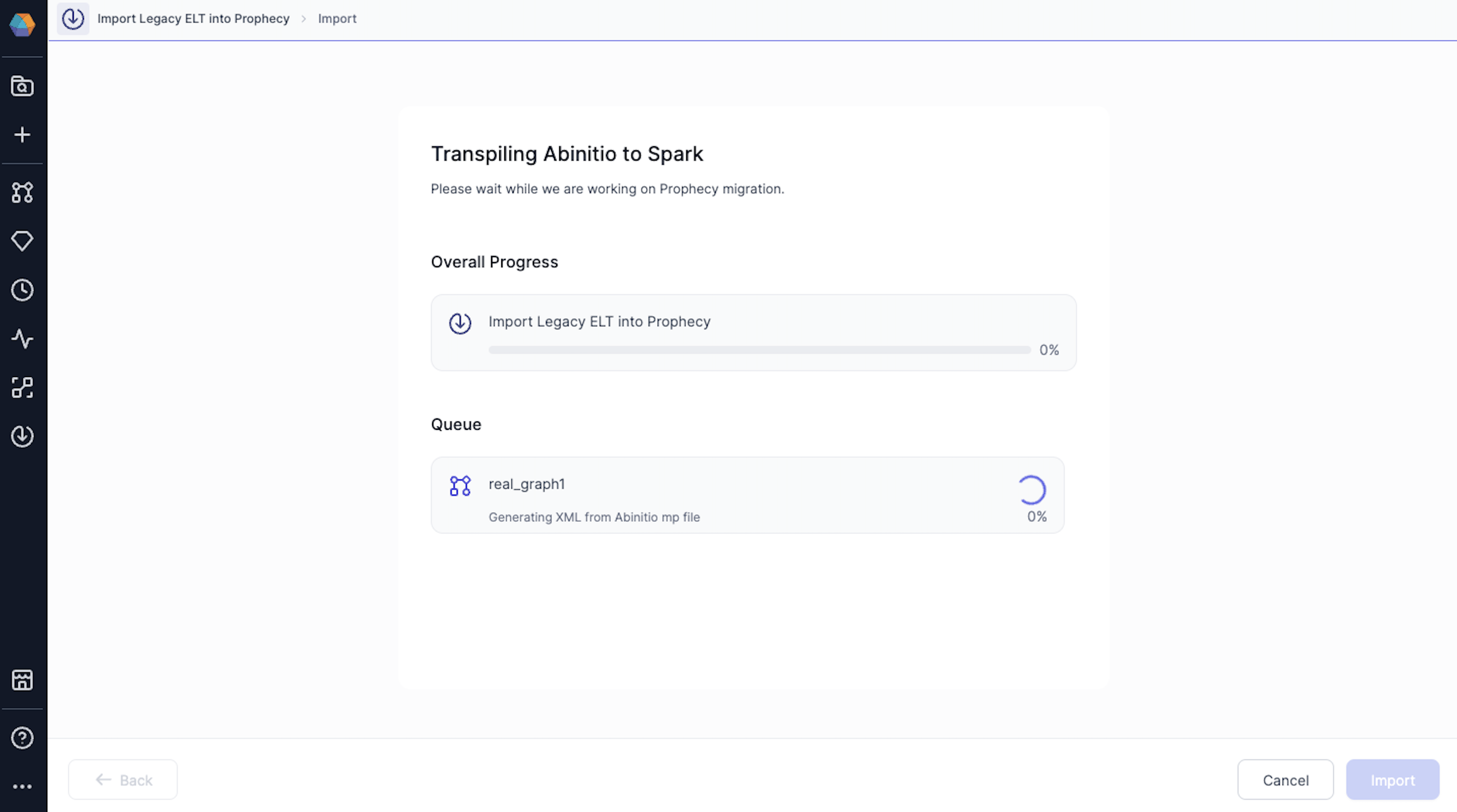 Here, you can track the progress of the transpilation process. The total time taken to transpile depends on the complexity of the graph that you have uploaded. If the graph is simple, transpilation will take a few seconds but complex graphs can take several minutes.
Here, you can track the progress of the transpilation process. The total time taken to transpile depends on the complexity of the graph that you have uploaded. If the graph is simple, transpilation will take a few seconds but complex graphs can take several minutes.
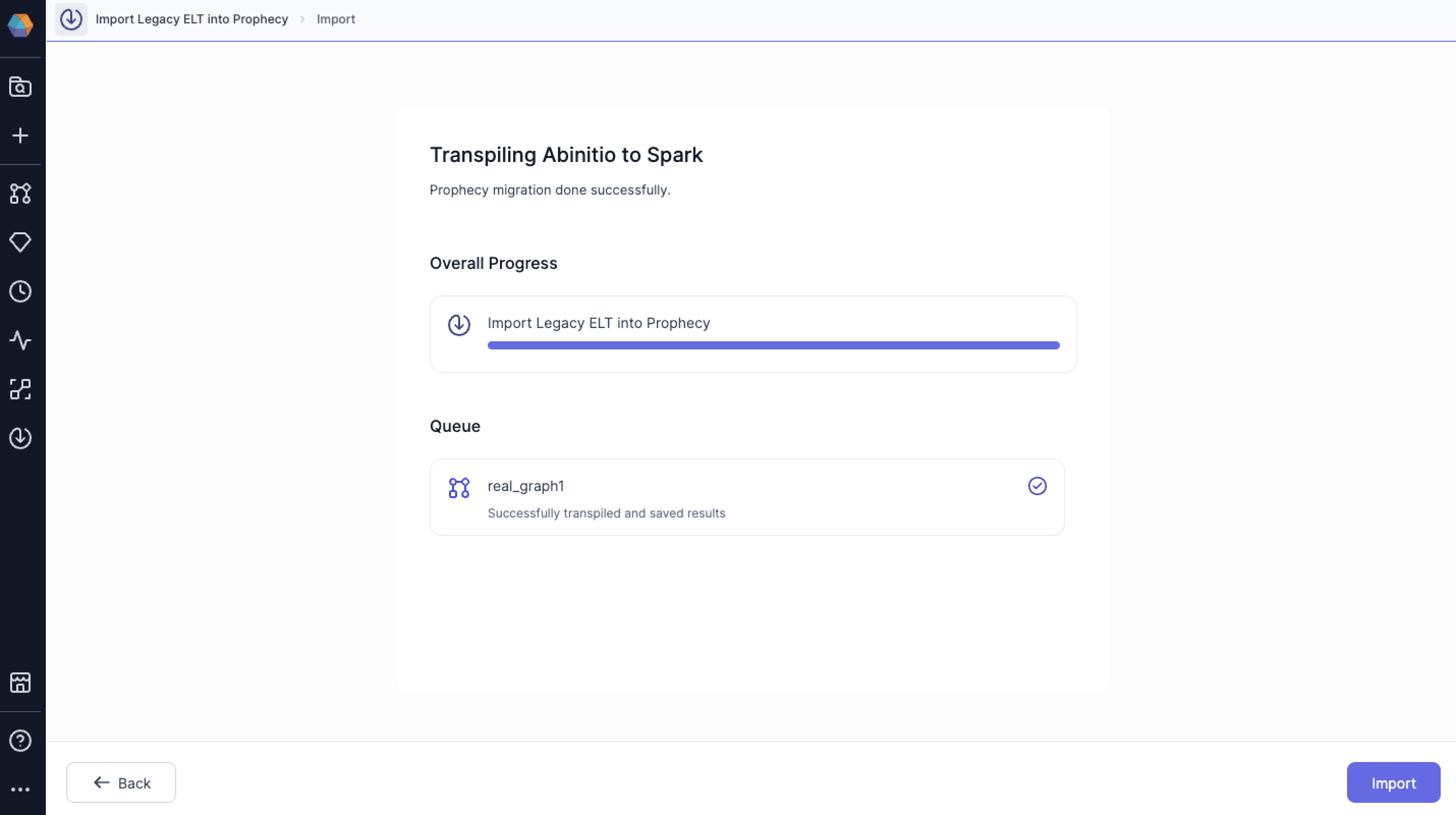 After the transpilation is complete, click on the Import button.
After the transpilation is complete, click on the Import button.
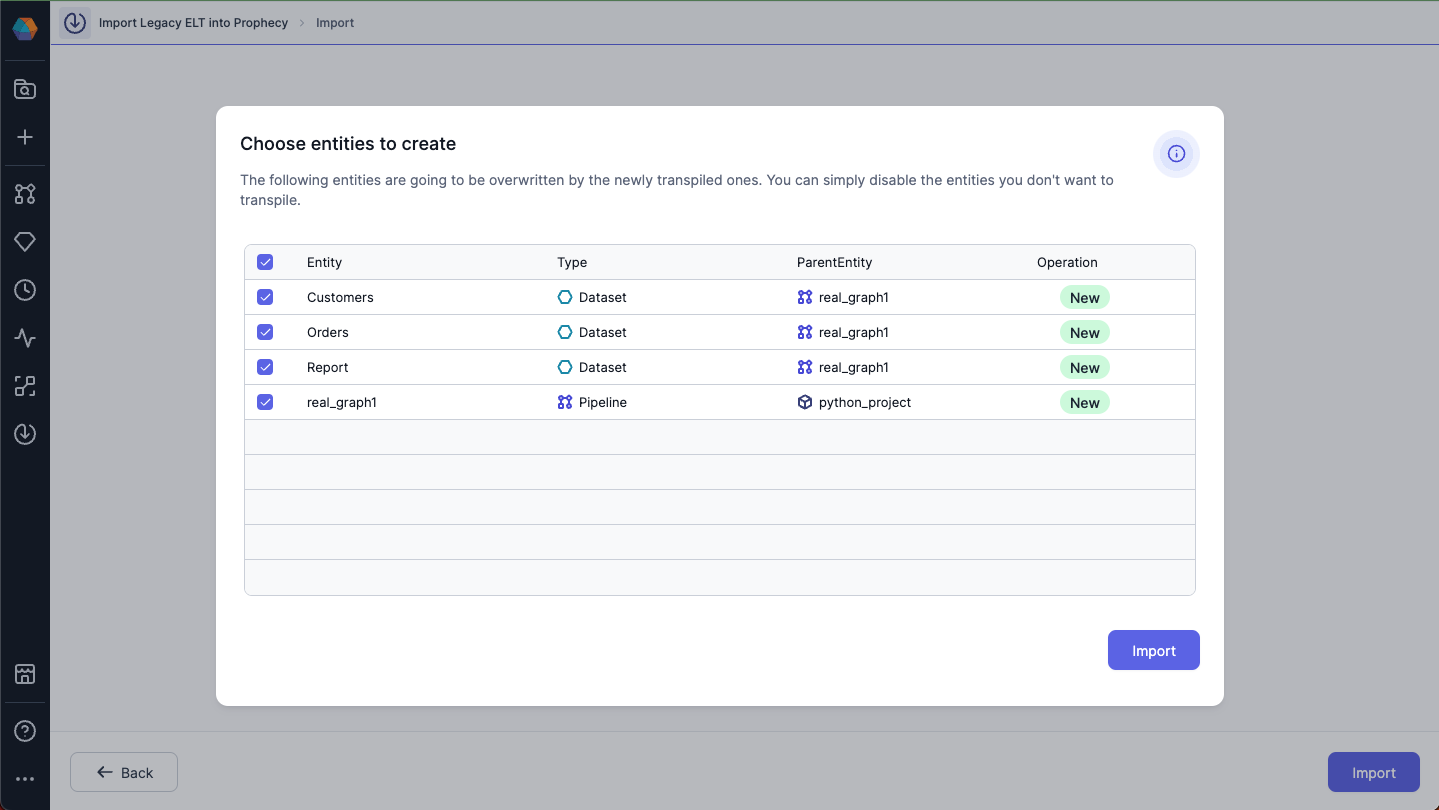 The purpose of the above screen is to help you resolve conflicts if any components already exist in the project. Deselect the entities that are not required. As you are using a new project, click on the Continue button.
The purpose of the above screen is to help you resolve conflicts if any components already exist in the project. Deselect the entities that are not required. As you are using a new project, click on the Continue button.
4. Bundle Overview
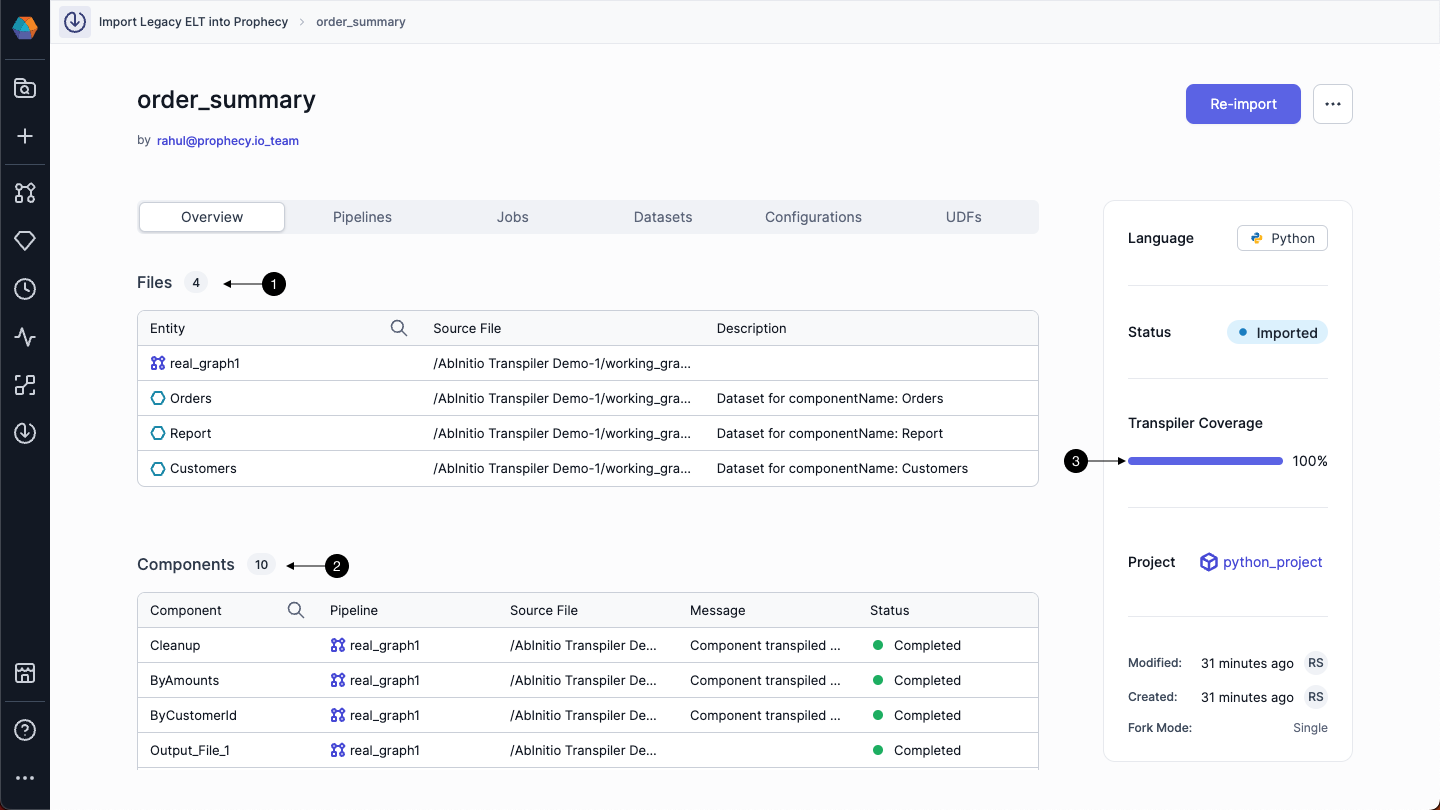 After the bundle is imported, you will be redirected to the overview section. Here, you will see the overall summary of the transpilation process. (1) shows the pipelines that were created in Prophecy. (2) shows the pipeline components - the individual transformation steps that we call “Components” - with a status column. In case the Transpiler was not able to read any Ab Initio component, the same would be displayed here with Failed status. (3) shows the overall transpiler coverage %.
After the bundle is imported, you will be redirected to the overview section. Here, you will see the overall summary of the transpilation process. (1) shows the pipelines that were created in Prophecy. (2) shows the pipeline components - the individual transformation steps that we call “Components” - with a status column. In case the Transpiler was not able to read any Ab Initio component, the same would be displayed here with Failed status. (3) shows the overall transpiler coverage %.
 Now click on the (1) icon to check the pipeline that has been transpiled by the Transpiler. Based on historical results, Prophecy Transpiler can convert the Ab Initio graphs correctly up to 80%.
Now click on the (1) icon to check the pipeline that has been transpiled by the Transpiler. Based on historical results, Prophecy Transpiler can convert the Ab Initio graphs correctly up to 80%.
 With the magic of Transpiler, the Ab Initio graph has been converted into a simple visual graph - a Pipeline. All Ab Initio components and functions will be mapped to equivalent Prophecy entities.
With the magic of Transpiler, the Ab Initio graph has been converted into a simple visual graph - a Pipeline. All Ab Initio components and functions will be mapped to equivalent Prophecy entities.
 Prophecy has also generated optimal high-performance open source Spark code for you.
Prophecy has also generated optimal high-performance open source Spark code for you.
5. Run Pipeline
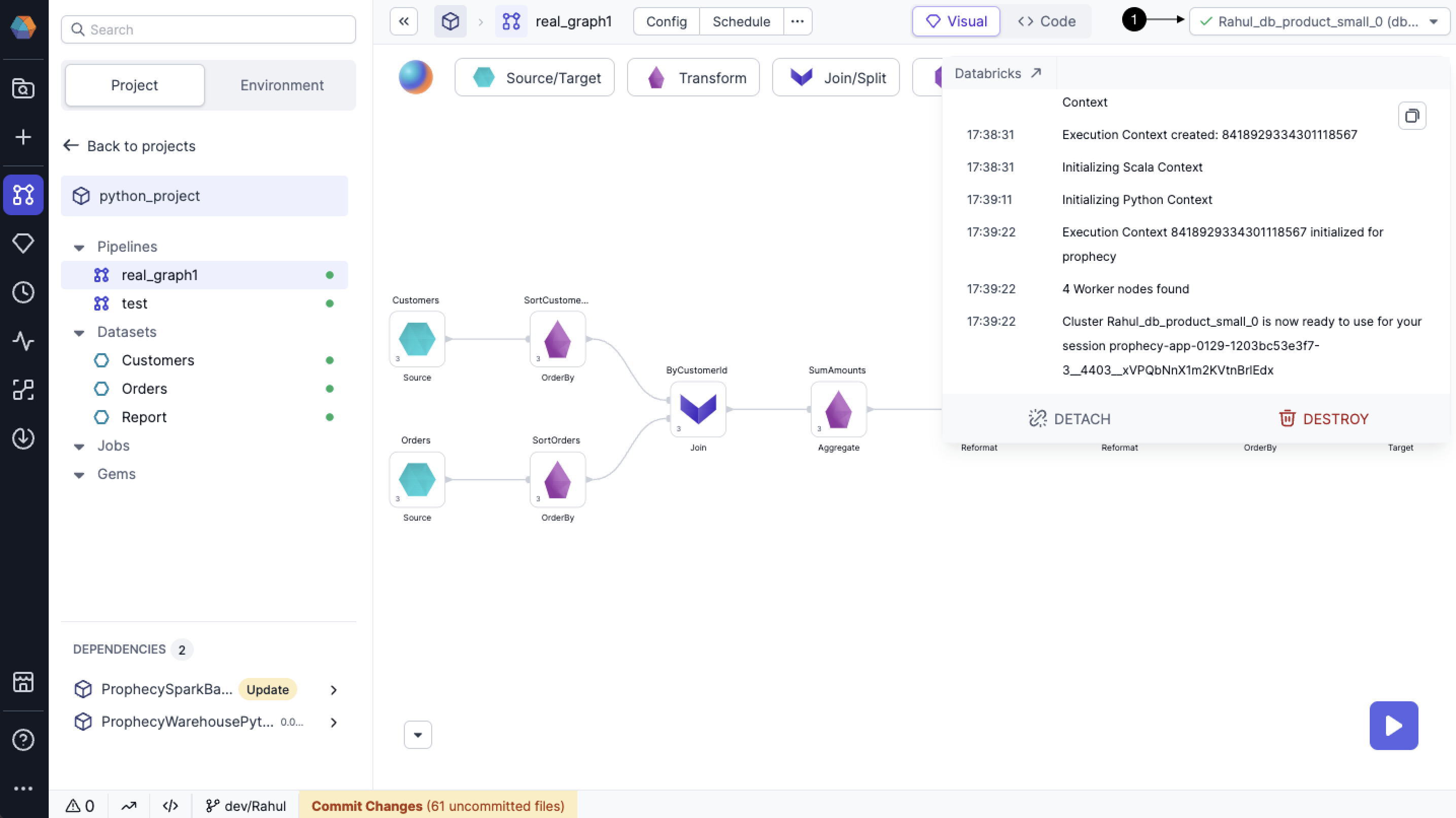 To run the pipeline, let’s first connect to a (1) fabric where the pipeline will be executed using the open-source Spark code.
After the fabric is connected, let’s change the file path of all the data components as Prophecy modernizes your legacy solutions to cloud alternatives. For this example, I will be reading files from Databricks, but you can connect any source of your choice.
To run the pipeline, let’s first connect to a (1) fabric where the pipeline will be executed using the open-source Spark code.
After the fabric is connected, let’s change the file path of all the data components as Prophecy modernizes your legacy solutions to cloud alternatives. For this example, I will be reading files from Databricks, but you can connect any source of your choice.

- Click on the source component.
- Choose the file type from where you will read the data. This example reads from a CSV file stored in Databricks.
- Provide the file location that points to the correct file in Databricks.
- Click Properties → Infer Schema and verify whether the schema of the data is correct.
- Click on the Preview → Load to preview the data that is being read by the component. This helps you to crosscheck whether you are referring to the correct data table or not.
- If everything looks good, then go ahead and click on the Save button.
Similarly, repeat the above steps for changing the file paths for all the source and target components in your pipeline.
A Target in Prophecy represents the data being written to a target storage location.
 Now run the pipeline by clicking on the Run button.
Now run the pipeline by clicking on the Run button.
 After the pipeline runs successfully, you will be able to see the data at each stage by clicking the interim icon.
After the pipeline runs successfully, you will be able to see the data at each stage by clicking the interim icon.
What’s next?
Great work! 🎉
You’ve successfully migrated your first legacy graph to the cloud using Prophecy Transpiler in a few minutes without any manual help. Take a moment to appreciate your accomplishment 🥳.
To continue learning and expanding your skills with Prophecy, explore other tutorials within our documentation, or apply your newfound knowledge to address real-world business challenges!