Parameters
| Parameter | Description |
|---|---|
| DataFrame | Input DataFrame |
| Row to keep |
|
| Deduplicate columns | Columns to consider while removing duplicate rows (not required for Distinct Rows) |
| Order columns | Columns to sort DataFrame on before de-duping in case of First and Last rows to keep. Sorting options:
|
Examples
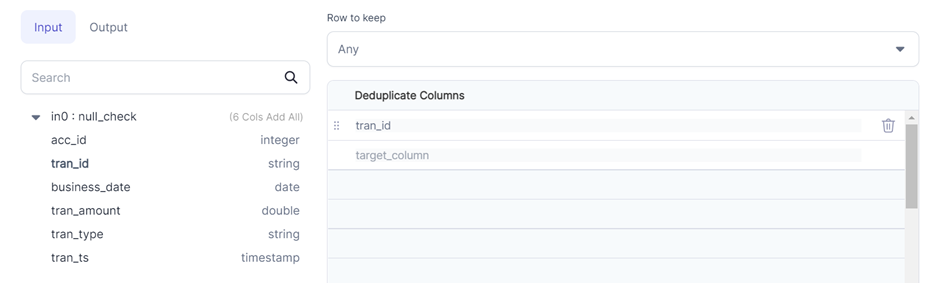
Rows to keep: Any
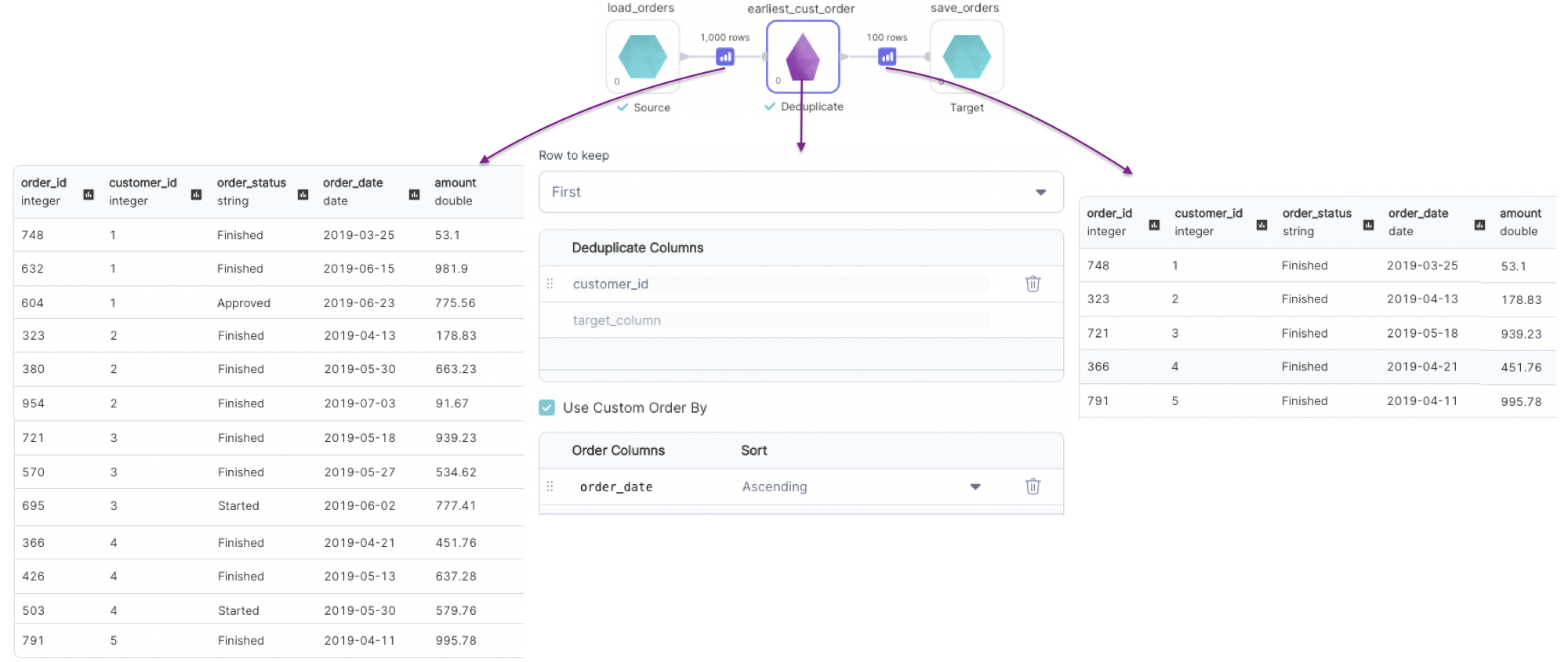
Rows to keep: First
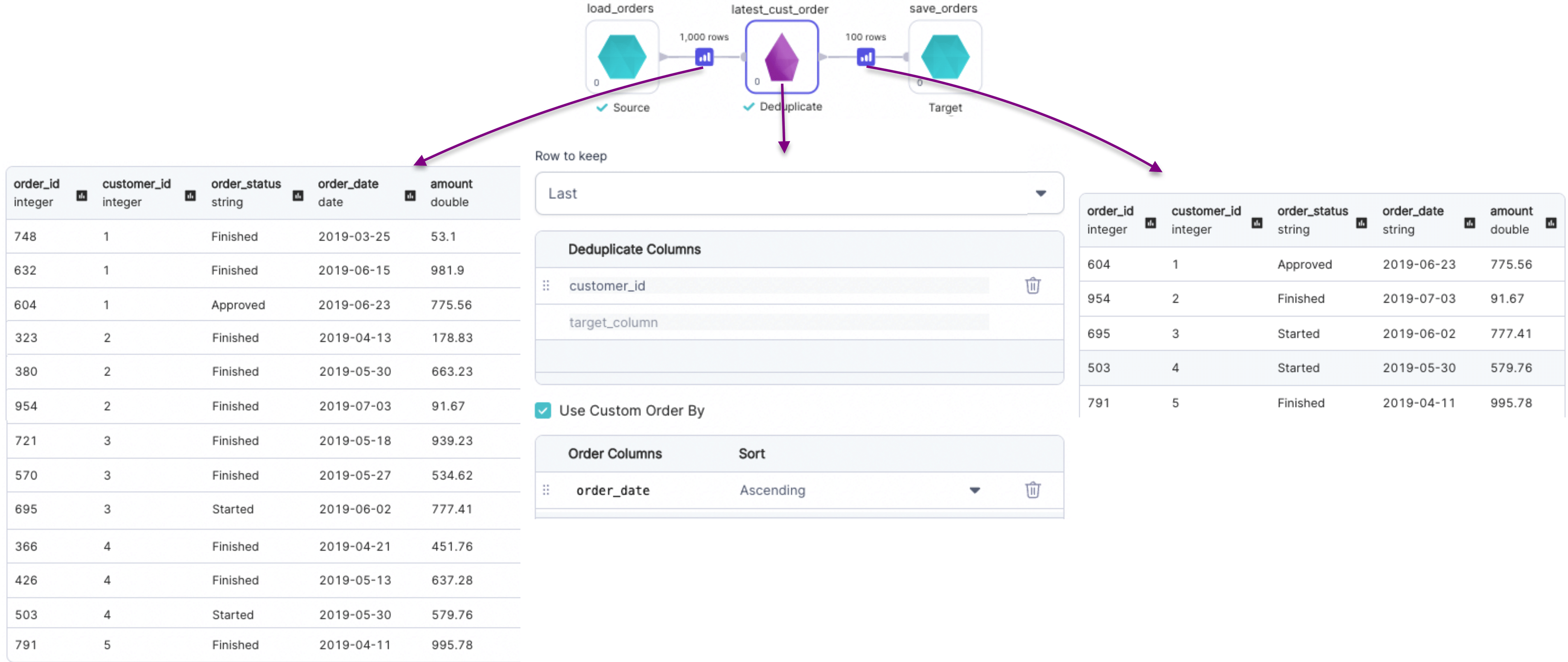
Rows to keep: Last
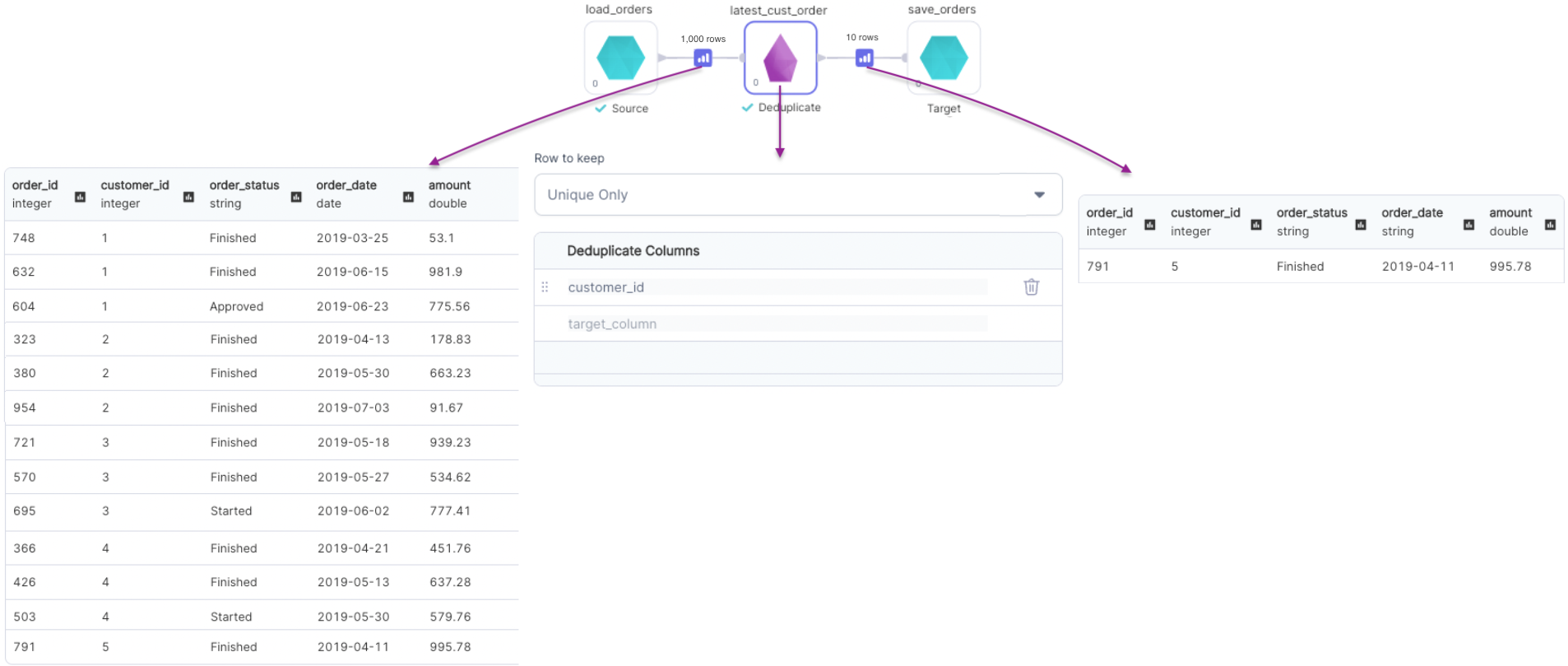
Rows to keep: Unique Only
Rows to keep: Distinct Rows